LLMTest
AI proxy that benchmarks prompts on real tasks, routes requests across models, and handles failover when provider APIs degrade.

AI Project Details
LLMTest review: AI proxy that benchmarks prompts on real tasks, routes requests across models, and handles failover when provider APIs degrade.
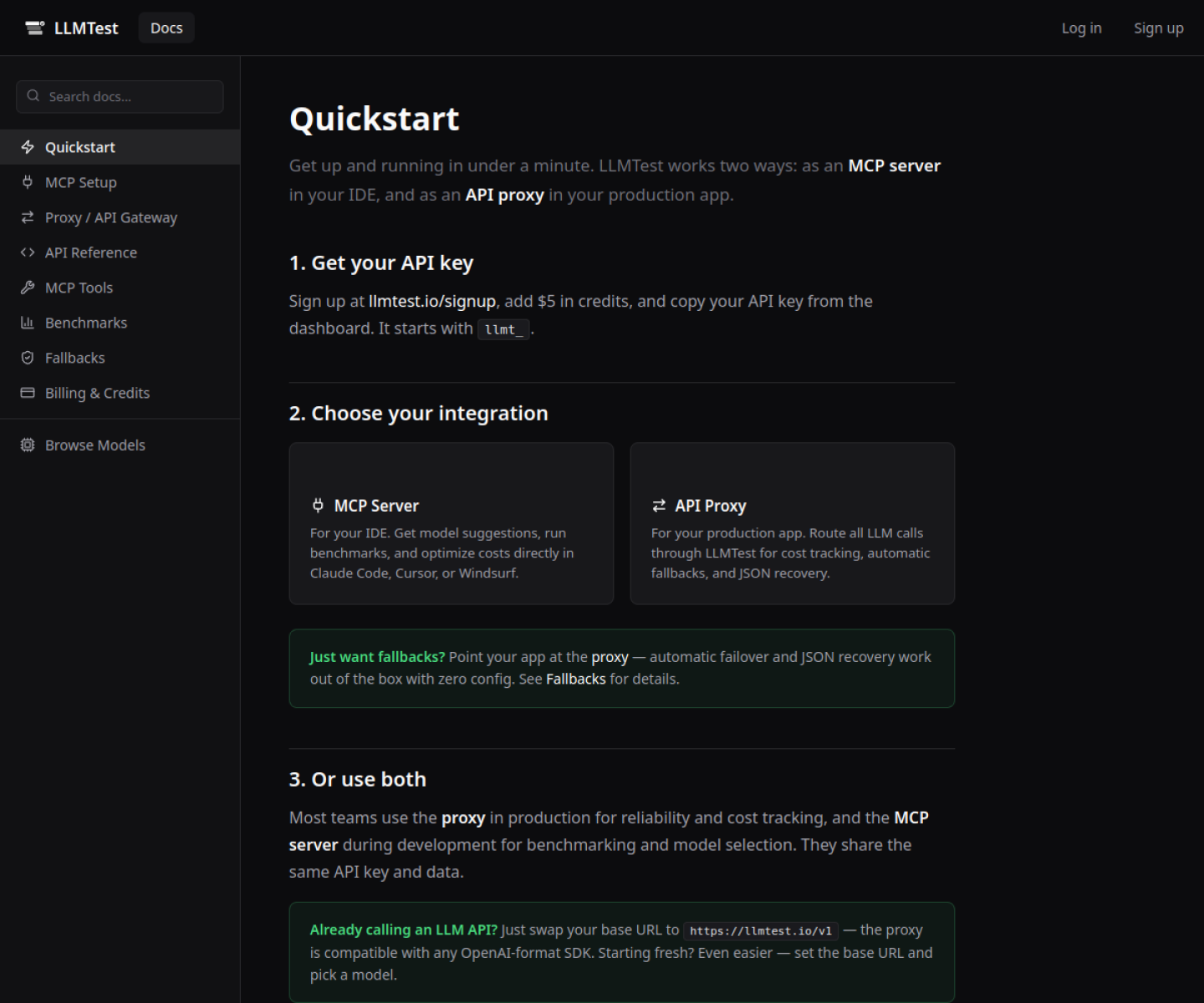
LLMTest is aimed at developers building ai features who want cost and quality controls without maintaining separate routing, fallback, and benchmarking systems. The current product materials describe a workflow built around point an openai-format client or mcp-capable editor at llmtest, define the quality bar for a flow, and let the gateway pick models, retry on failures, and report costs against real prompts. That makes the page easier to read as an operating model, not just a brand claim.
Why it is timely
LLMTest is unusually explicit that model choice should be based on real prompts, not generic leaderboard scores. The product combines routing, quality judging, model radar, and IDE or MCP suggestions into one operating surface. Its public pricing is simpler than many routing products because the commercial model is a transparent usage markup rather than a layered plan matrix.
How the workflow works in practice
A sensible first pass is to start from the product's main entry point and test the shortest path to value. For LLMTest, that means users should point an openai-format client or mcp-capable editor at llmtest, define the quality bar for a flow, and let the gateway pick models, retry on failures, and report costs against real prompts. If that loop reduces review drag, coordination, or governance work, the product is doing something real.
Where LLMTest stands out
| Evaluation angle | Fit | Why it matters | | --- | --- | --- | | Best-fit user | High | Developers building AI features who want cost and quality controls without maintaining separate routing, fallback, and benchmarking systems. | | Core workflow clarity | High | Point an OpenAI-format client or MCP-capable editor at LLMTest, define the quality bar for a flow, and let the gateway pick models, retry on failures, and report costs against real prompts. | | Switching cost reducer | Medium to high | LLMTest is unusually explicit that model choice should be based on real prompts, not generic leaderboard scores. | | Adoption risk | Medium | The value depends on routing enough traffic for benchmarking and fallback logic to matter; very small apps may not need the layer. |
Practical use cases
- Reducing AI feature costs without manually comparing every provider
- Adding automatic provider failover to production prompt flows
- Benchmarking prompts against current model pricing and quality tradeoffs
Limits and buying notes
The value depends on routing enough traffic for benchmarking and fallback logic to matter; very small apps may not need the layer. Teams still need to validate how much automatic prompt rewriting or model switching they want in production flows. Pricing status today: LLMTest's official pricing says there is one pay-as-you-go plan with a 10 percent markup over model base cost, credit top-ups from $5 upward, and no monthly fee or commitment.
FAQ
What is LLMTest best for?
LLMTest is strongest when reducing ai feature costs without manually comparing every provider matters more than a generic AI demo. The official product materials position it around a concrete workflow rather than a blank chatbot shell.
Who should try LLMTest first?
Developers building AI features who want cost and quality controls without maintaining separate routing, fallback, and benchmarking systems. Teams with a real workflow match will get value faster than general curiosity users.
What should buyers verify before adopting LLMTest?
The value depends on routing enough traffic for benchmarking and fallback logic to matter; very small apps may not need the layer. Teams still need to validate how much automatic prompt rewriting or model switching they want in production flows. Pricing, privacy, and workflow fit should be checked directly on the current product before rollout.
Reviewed sources
- https://llmtest.io/
- https://llmtest.io/docs
- https://llmtest.io/llm-pricing-comparison
FAQ
What is LLMTest best for?
LLMTest is strongest when reducing ai feature costs without manually comparing every provider matters more than a generic AI demo. The official product materials position it around a concrete workflow rather than a blank chatbot shell.
Who should try LLMTest first?
Developers building AI features who want cost and quality controls without maintaining separate routing, fallback, and benchmarking systems. Teams with a real workflow match will get value faster than general curiosity users.
What should buyers verify before adopting LLMTest?
The value depends on routing enough traffic for benchmarking and fallback logic to matter; very small apps may not need the layer. Teams still need to validate how much automatic prompt rewriting or model switching they want in production flows. Pricing, privacy, and workflow fit should be checked directly on the current product before rollout.